I. Scenario Introduction
Scenario - URL Deduplication Filtering at Billion-Scale Data Volume
Taking large-scale web crawlers as an example, in large-scale web crawlers targeting specific keywords, the number of URLs to be crawled may reach hundreds of millions. Duplicate URLs not only waste crawling resources but may also cause crawlers to fall into infinite loops or invalid crawling, severely affecting crawling efficiency and data quality.
Traditional Solutions
- Store in database with unique constraint
- I/O bottleneck
- Use cache, such as HashSet
- High memory overhead
Solution Optimization
Considering that URL crawler deduplication allows for false positives, a small portion of data misjudgment is completely acceptable at large data volumes.
- Use Bitmap with single-hash compression storage, utilizing a binary array to record whether a URL has appeared, occupying less memory space.
- Memory usage estimation for 10 billion URLs: with 1% false positive rate, data volume , bitmap size , occupying 125GB.
- Further optimize the bitmap, i.e., Bloom Filter, utilizing multiple ($k$) hash functions to map each element to multiple ($k$) bits in the binary array, representing one element with multiple bits.
II. Bloom Filter Introduction
Concept
Bloom Filter is a probabilistic data structure based on Bit Array. It can efficiently detect whether an element "might exist" or "definitely does not exist".
- Space Efficient: Uses bit array to store data, greatly saving space.
- Fast Query Speed: Insert and query operations both have constant time complexity , where is the number of hash functions.
- Possible False Positives: There is a possibility of misjudgment, i.e., possibly mistakenly believing that an element not inserted exists in the set (False Positive), but it will never misjudge that an element does not exist.
Diagram
Initialize Bloom Filter
image.png|500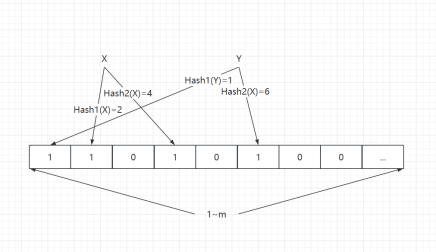
image.png|500
Query: Definitely Does Not Exist vs Might Exist
Definitely Does Not Exist: Query and insert Z
When querying Z, only one bit is found to be 1 and the other bit is 0, proving it definitely does not exist.
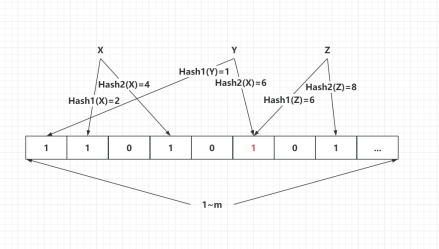
image.png|500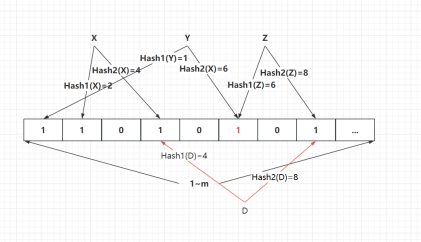
image.png|500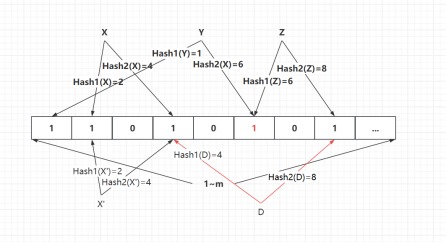
image.png|500
Parameters
Parameter Meanings
- Number of elements to be inserted
- Bit array length
- Number of hash functions
- False positive rate
Derivation Formulas
- Probability that a certain bit remains 0 after inserting 1 element with hashes:
- Probability that a certain bit remains 0 after inserting elements with hashes:
- Probability that a certain bit is set to 1 after inserting elements with hashes:
- Probability that bits obtained by hashing 1 element times are all set to 1:
- Derivable false positive rate
Parameter Estimation Given the number of elements to be inserted and false positive rate :
- Bit array length
- Number of hash functions
Characteristics
Add, Query, No Delete It is obvious that Bloom Filter cannot support deletion operations, because multiple elements may hash to the same position in the Bloom Filter. Refer to the Bloom Filter diagram above.
Space Occupancy Memory usage estimation for 10 billion URLs, 1% false positive rate:
- For Bitmap: length , occupying 125GB
- For Bloom Filter: bit array length , occupying approximately 12GB
III. Bloom Filter in Practice - Using Guava Library
In actual projects, the Bloom Filter provided in Google's Guava library is typically used. Guava Maven Repository
Small Case Study
Introduce Guava dependency
<!-- https://mvnrepository.com/artifact/com.google.guava/guava -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>32.1.2-jre</version>
</dependency>
Core methods of Guava library's Bloom Filter:
put(): Insert elementmightContain(): Determine if element might exist
Example case:
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class BloomFilterExample
{
private static Integer expectedInsertions = 10000000;
private static Double fpp = 0.01;
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), expectedInsertions, fpp);
public static void main(String[] args)
{
for (int i = 0; i < expectedInsertions; i++)
{
bloomFilter.put(i);
}
int count = 0;
for (int i = expectedInsertions; i < expectedInsertions * 2; i++)
{
if (bloomFilter.mightContain(i))
{
count++;
}
}
System.out.println("一共误判了:" + count);
}
}
Insert data, judge data, false positives occurred 100075 times.
IV. Guava BloomFilter Source Code Deep Analysis
BloomFilter Class
Encapsulates the core logic of Bloom Filter, such as adding, querying elements, initialization parameter calculation (such as bitmap size, number of hash functions), etc.
- create(Funnel, int, double) Lightweight user interface
- create(Funnel, long, double) Advanced interface
- create(funnel, expectedInsertions, fpp, Strategy) Core implementation
Factory creation of BloomFilter:
public static <T extends @Nullable Object> BloomFilter<T> create(
Funnel<? super T> funnel, int expectedInsertions, double fpp) {
return create(funnel, (long) expectedInsertions, fpp);
}
public static <T extends @Nullable Object> BloomFilter<T> create(
Funnel<? super T> funnel, long expectedInsertions, double fpp) {
return create(funnel, expectedInsertions, fpp, BloomFilterStrategies.MURMUR128_MITZ_64);
}
Core methods:
public boolean put(@ParametricNullness T object) {
return strategy.put(object, funnel, numHashFunctions, bits);
}
public boolean mightContain(@ParametricNullness T object) {
return strategy.mightContain(object, funnel, numHashFunctions, bits);
}
static int optimalNumOfHashFunctions(long n, long m) {
// (m / n) * log(2), but avoid truncation due to division!
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
static long optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
Funnel Interface
The main responsibility of the Funnel interface is to "funnel" an object's state into a PrimitiveSink, thereby producing a continuous byte sequence, so that custom structures can use Bloom Filters.
public interface Funnel<T> {
void funnel(T from, PrimitiveSink into);
}
- T from: The object to be converted.
- PrimitiveSink into: The container receiving the object data. PrimitiveSink provides various methods to write primitive data types and strings into a unified byte stream.
Guava comes with native Funnels, such as integerFunnel(), stringFunnel(Charset), byteArrayFunnel(), etc.
Case Study
Goods
@Data
@AllArgsConstructor
public class Goods {
private final int id;
private final String name;
}
PojoBloomFilter
public static void main(String[] args)
{
// Expected to insert 10000 Person objects, false positive rate set to 0.01
BloomFilter<Goods> personBloomFilter = BloomFilter.create(
PersonFunnel.INSTANCE,
10000,
0.01
);
// Create and insert a Goods object
Goods apple = new Goods(1, "apple");
personBloomFilter.put(apple);
// Query whether a certain object might exist
Goods queryGoods1 = new Goods(1, "apple");
if (personBloomFilter.mightContain(queryGoods1))
{
System.out.println(queryGoods1 + "可能存在于布隆过滤器中");
}
else
{
System.out.println(queryGoods1 + "肯定不存在于布隆过滤器中");
}
Goods queryGoods2 = new Goods(2, "banana");
if (personBloomFilter.mightContain(queryGoods2))
{
System.out.println(queryGoods2 + "可能存在于布隆过滤器中");
}
else
{
System.out.println(queryGoods2 + "肯定不存在于布隆过滤器中");
}
}
Funnel Function
- Ensure Consistency: Funnel ensures that as long as it is the same structure, the pre-processing before hashing is consistent.
- Control Granularity: For custom classes, if you want to use Bloom Filter, you can choose which fields to inject. For example, Goods injects id and name.
Strategy Interface (Default Implementation: MURMUR128MITZ64)
The Strategy interface defines the hash strategy, element insertion, and query specific operations of the Bloom Filter. Default uses MURMUR128MITZ64:
- MURMUR128: MurmurHash3 128-bit variant
- MITZ: Derived from Google engineer Mitz Pettel, designed the following "double hashing" technique
- 64: Uses 64 bits each time
It can be found that it does not actually use hash functions, and the implementation uses one Hash and splits it into two fields. "Less Hashing, Same Performance: Building a Better Bloom Filter" proposed an optimization algorithm that only needs to calculate two independent hash functions to construct a Bloom Filter equivalent to using multiple hash functions: $$gi(x)=h1(x)+i·h_2(x)$$
public <T extends @Nullable Object> boolean put(
@ParametricNullness T object,
Funnel<? super T> funnel,
int numHashFunctions,
LockFreeBitArray bits) {
long bitSize = bits.bitSize();
byte[] bytes = Hashing.murmur3_128().hashObject(object, funnel).getBytesInternal();
long hash1 = lowerEight(bytes);
long hash2 = upperEight(bytes);
boolean bitsChanged = false;
long combinedHash = hash1;
for (int i = 0; i < numHashFunctions; i++) {
// Make the combined hash positive and indexable
bitsChanged |= bits.set((combinedHash & Long.MAX_VALUE) % bitSize);
combinedHash += hash2;
}
return bitsChanged;
}
The strategy passes index = (combinedHash & Long.MAX_VALUE) % bitSize) to BitArray. The purpose is to make combinedHash positive, otherwise modulo with bitSize cannot be performed (negative index exception).
BitArray Module
BitArray is the core of the Bloom Filter's underlying implementation, responsible for the storage and management of the bit array.
static final class LockFreeBitArray {
private static final int LONG_ADDRESSABLE_BITS = 6;
final AtomicLongArray data;
private final LongAddable bitCount;
LockFreeBitArray(long bits) {
checkArgument(bits > 0, "data length is zero!");
// Avoid delegating to this(long[]), since AtomicLongArray(long[]) will clone its input and
// thus double memory usage.
this.data = new AtomicLongArray(Ints.checkedCast(LongMath.divide(bits, 64, RoundingMode.CEILING)));
this.bitCount = LongAddables.create();
}
boolean set(long bitIndex) {
if (get(bitIndex)) {
return false;
}
int longIndex = (int) (bitIndex >>> LONG_ADDRESSABLE_BITS);
long mask = 1L << bitIndex; // only cares about low 6 bits of bitIndex
long oldValue;
long newValue;
do {
oldValue = data.get(longIndex);
newValue = oldValue | mask;
if (oldValue == newValue) {
return false;
}
} while (!data.compareAndSet(longIndex, oldValue, newValue));
// We turned the bit on, so increment bitCount.
bitCount.increment();
return true;
}
boolean get(long bitIndex) {
return (data.get((int) (bitIndex >>> LONG_ADDRESSABLE_BITS)) & (1L << bitIndex)) != 0;
}
}
- Uses long(64 bit) array
- bitCount is the number of bits set to 1, using native method Long.bitCount() to统计负载程度
- get method: index logically right-shifted to get long element index, index uses AND to get specific index after modulo
- set method: uses compareAndSet for atomic update
- putAll method: uses OR operation on two BitArrays, used for Bloom Filter merging
V. Bloom Filter Derived Technologies
Counting Bloom Filter
- Allows deletion operations based on ordinary Bloom Filter
- Implemented through bit counting method
- Disadvantage is larger space occupation
Bloomfilter
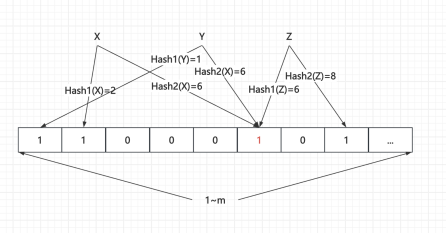
image.png|500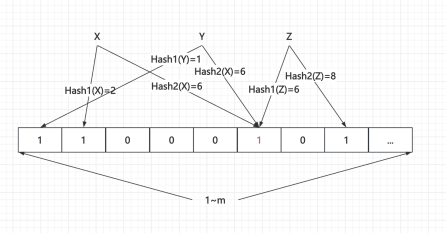
image.png|500
Periodic Reconstruction of Bloom Filter
- Periodic reconstruction
- Delete old Bloom Filter
- Reconstruct new Bloom Filter
VI. Practical Scenarios
Large-scale Product IDs
- User requests a product
- Unlike crawler URL filtering, no mistakes allowed
- Use database?
- Use cache?
- Use Bloom Filter?
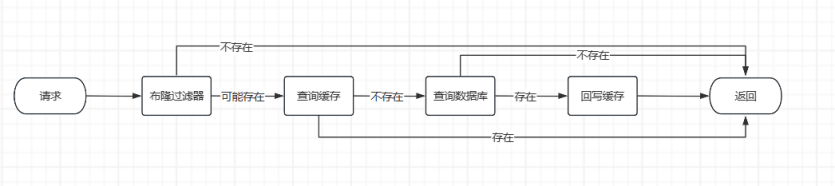
image.png|700