Mainstream Distributed ID Solutions
1. Introduction
In high-throughput systems, such as e-commerce platforms during promotional periods, it is crucial to quickly assign a globally unique and non-conflicting number to each order.
If relying solely on database auto-increment IDs, once throughput increases, the database becomes a bottleneck in the system; in multi-instance deployment scenarios, it is impossible to guarantee that IDs generated by each node are globally unique and conflict-free; completely randomly generated out-of-order IDs may cause frequent page splits in database indexes; and ID exposure may reveal system privacy information, such as business volume.
This is what distributed IDs need to solve: global uniqueness, high availability and high performance, trend increment, and security.
Thus many schemes have emerged: bit-allocated Snowflake algorithm, batch ID generation segment mode, purely locally generated UUID...
2. ID Forms: Four Main Forms and Characteristics of Distributed IDs
There are roughly four types of ID forms:
Time-series based: SnowFlake, UUID v1/v6/v7
They use timestamps as high-order bits, concatenated with random numbers, sequence numbers, and node numbers, ensuring temporal ordering.
Advantages: Time-ordered, locally generated
Disadvantages: Clock rollback, time leakage
Random-based: UUID v4 Does not depend on time or machine, completely random. Advantages: Random, does not expose information, locally generated Disadvantages: Unordered, unfriendly to indexes
Segment distribution-based: DB, Leaf Segment, TinyID, Redis Fetch a batch of numbers (segment) into memory at once, and increment locally to issue numbers. Advantages: Easy to scale, trend-ordered, smoother and more stable through dual Buffer optimization. Disadvantages: Exposes business volume, depends on DB or Redis to maintain allocation volume, can only guarantee trend ordering for horizontal scaling.
Ring buffer pre-fill based: uID-generator References segment and Snowflake algorithm, uses Snowflake's bit allocation concept to build ordered IDs, and fills a ring array as a cache pool. Its timestamp is only set during initialization, and subsequently only increments when filling the cache and obtains all IDs for that moment. Advantages: Ordered, locally generated, can break through the 1s sequence number limit to achieve high concurrency. Disadvantages: The timestamp in the ID cannot represent real time, but can pre-borrow future time.
3. Specific Implementations: Analysis of Seven Distributed ID Generation Schemes
3.1 SnowFlake: Twitter's Open Source Bit-Allocated Time-Series ID Solution
Snowflake algorithm is a distributed ID generation algorithm open-sourced by Twitter. The core is dividing space and identifying respectively.
Structure and Bit Allocation

SnowFlake Algorithm Bit Allocation Structure Diagram|500
The 41-bit timestamp is at millisecond level, can accommodate roughly 69 years. Placing the timestamp in high-order bits can ensure that IDs generated in a distributed manner are generally increasing.
The two 5-bit identifiers can provide machine IDs. The 12-bit auto-increment sequence number can represent IDs.
Therefore theoretically, the IDs/s obtained by one machine using Snowflake algorithm is
Issues
Heavily dependent on time. If clock rollback phenomenon occurs, it will cause ID anomalies, such as duplication, reverse order, and other issues.
Clock Rollback
- Block directly until lastTimestamp
- Maintain an offset that grows during rollback, actually use logicalTimestamp=currentTimestamp+offset
- Borrow high-order bits as rollback tag
3.2 Database Generation: Database Auto-Increment Based ID Solution
Utilize database auto-increment to generate auto-increment IDs, by setting different initial values for different machines and the same step size equal to the machine count.
Defects
Heavily dependent on DB, not easy to scale, because step size adopts machine count. If single-machine DB, it limits the upper bound of number issuance. If multi-machine, it can only guarantee trend increment, and maintenance is difficult. DB pressure is high, because every ID acquisition requires read-write.
3.3 UUID Series: Universally Unique Identifier
UUID (Universally Unique IDentifier), also called GUID, consists of 32 hexadecimal digits, in the form xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx, where M and N represent version and variant respectively.
UUID v1
60bit timestamp + 14bit clock sequence + 48bit node (commonly MAC or pseudo-random)
v1's 60bit timestamp (unit 100ns, since 1582-10-15) is divided into time_low(32) + time_mID(16) + time_high(12)
UUID v4
Except for version/variant bits, almost completely random (122bit entropy) Does not expose time or host information JDK's UUID.randomUUID() is v4 version
UUID v6
v1's rearranged version, sorted by high-order time for better database insertion suitability.
60bit timestamp + 14bit clock sequence + 48bit node (commonly MAC or pseudo-random)
60bit timestamp divided into time_high(32)+time_mID(16)+time_low(12)
UUID v7
48bit millisecond-level timestamp + 12bit randa + variant + randb (remaining random/monotonic fields)
UUID v7 absorbed ULID concepts
ULID Universally Unique Lexicographically Sortable Identifier
48 bits │ 80 bits 48 bit millisecond-level timestamp 80 bit secure random number
Notably, ULID adopts Base32 encoding (numbers + letters, removing
I,L,O,U), different from UUID's Base16 encoding, finally appearing as 26-character strings, such as01FZ4Q3YSJH9X8HRXW4E7JKX4N
3.4 Meituan Leaf: High-Availability Distributed ID Generation Service
Meituan Tech: Leaf——Meituan-Dianping Distributed ID Generation System(https://tech.meituan.com/2017/04/21/mt-leaf.html?utm_source=chatgpt.com)
Leaf Segment
Optimized on the database scheme. The original scheme requested the database once per number. Now optimized to use a proxy server to fetch in batches, each time obtaining a segment of numbers, and after exhaustion, fetching another segment in batches.
| Field | Type | Null | Key | Default | Extra | Comment |
|---|---|---|---|---|---|---|
| biz_tag | varchar(64) | NO | Primary | NULL | Business identifier (e.g., order_tag) | |
| max_ID | bigint unsigned | NO | 0 | Maximum ID already allocated | ||
| step | int unsigned | NO | 1000 | Segment size (batch step size each time) | ||
| desc | varchar(255) | YES | NULL | |||
| update_time | timestamp | NO | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP |
Use biz_tag to distinguish businesses. Each time fetch step numbers. Database read-write frequency is reduced from 1 to 1/step times.
Advantages
- IDs are trend auto-increment
- Can scale linearly
Disadvantages
- IDs are auto-increment, not random enough, will leak information
- When numbers are exhausted and fetching again in batches, there will be a large jitter
Dual Buffer Optimization
In this scheme, the entire number fetching does not look smooth. When the segment is exhausted and fetching the segment, there will be a large fluctuation in number fetching. To achieve non-blocking number fetching, consider asynchronously fetching the next segment when the current segment reaches a certain threshold, rather than waiting until the segment is exhausted and blocking to obtain a new segment when fetching numbers.
That is, two segment buffers. When the currently used segment reaches a certain threshold, asynchronously fetch the next segment. When the current segment is exhausted, directly switch to another segment to issue numbers, achieving stable number issuance.
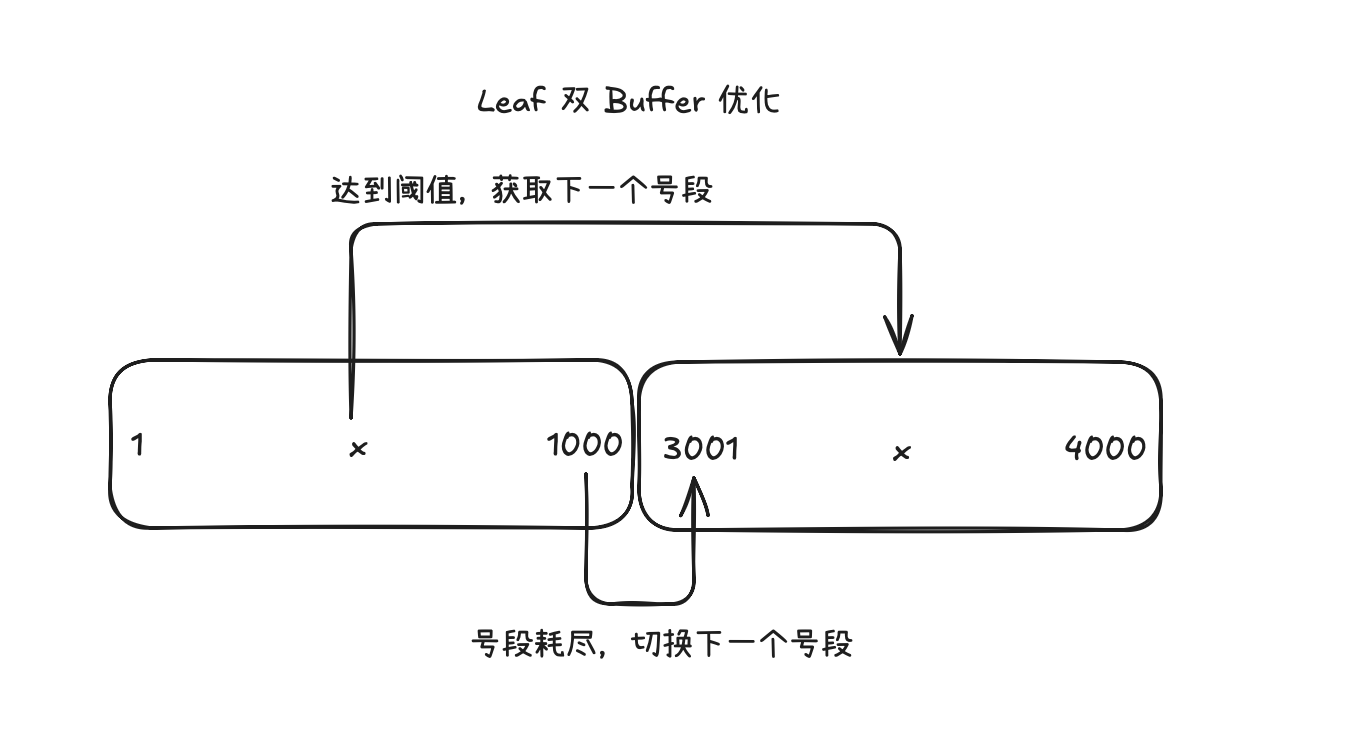
Meituan Leaf Dual Buffer Optimization Principle Diagram|500
Leaf SnowFlake
Leaf Segment scheme can stably obtain trend-incrementing IDs, but will leak data volume, so there is the Leaf SnowFlake scheme.
Still follows SnowFlake's bit allocation design.
Bit Allocation 1 | 41 | 10 | 12 1bit vacant 41bit millisecond-level timestamp 10bit workerID 12bit sequence number, 0~4095 per millisecond
Clock Rollback
Use ZooKeeper for time consistency and health detection.
/leaf_forever/{self}: Persistent node, stores the most recent reported system time (milliseconds) of this instance, used for startup and runtime comparison to detect large-step rollback/leaf_temporary/{self}: Ephemeral node, runtime periodic (e.g., every 3s) reporting of local time, while pulling all online node times, calculating mean or median
3.5 Didi TinyID: Segment Mode Supporting Multiple Master DBs
Similar to Leaf Segment in principle, also utilizes dual Buffer buffering, but additionally supports multiple master dbs. Even if segments are the same, there is no intersection, ID % delta == remainder
| ID | biz_type | max_ID | step | delta | remainder | version |
|---|---|---|---|---|---|---|
| 1 | order | 10000 | 1000 | 3 | 0 | 0 |
| 2 | order | 10000 | 1000 | 3 | 1 | 0 |
| 3 | order | 10000 | 1000 | 3 | 2 | 0 |
biz_type business ID
max_ID supports multiple maximum IDs
step step size, i.e., segment size
delta ID increment each time, used for supporting multiple dbs
remainder remainder, used for supporting multiple dbs
Example
A B C 3 master dbs
Can all obtain the segment (3000,4000], but each segment aligns to its own first first
first = start + ((end - start % delta + delta) % delta)
That is, each db's segment can only provide 1/delta portion
Can also implement such as only odd IDs, i.e., delta = 2, remainder = 1
3.6 Baidu uID generator: Snowflake Algorithm Based on Dual RingBuffer Optimization and Pre-fillable
Bit Allocation

Baidu uID-generator Bit Allocation Structure|500
1 | 28 | 22 | 13 1bit vacant 28bit second-level timestamp 22bit workerID 13bit sequence number, 0~8191 per second
DefaultUIDGenerator That is, ordinary SnowFlake
synchronized
获取当前时间
当前时间小于上次时间
抛异常,时钟回拨
当前时间等于上次时间
序列号自增,同时取模最大序列号(也就是 & 8191)
序列号等于 0(也就是超过当前秒所能供应的上限)
阻塞至下一秒并修改当前时间
当前时间是最新的
序列号置为 0
上次时间置为当前时间
构造 ID
CachedUIDGenerator Adopts dual RingBuffer, UID-RingBuffer for storing UID, Flag-RingBuffer for storing UID status (CANTAKE, CANPUT)
RingBuffer is a circular array, using tail producer pointer, cursor consumer pointer, capacity is the maximum sequence number supported per second, i.e., 8192.
Obtain ID directly from RingBuffer. Fill ID
- At program startup: fill RingBuffer with 8192 IDs
- During
getUID(): check capacity, if remaining IDs are less than a certain threshold, e.g., 50%, then fill it - Periodic filling
Generate ID by constructing the first ID through passed-in currentSecond, then fill ID list to single-second maximum sequence number. Fill ID by obtaining all IDs for the next second of lastSecond, filling one by one, until RingBuffer is full.
Defects In this scheme, lastSecond may differ from real time. Except when initialized to real time, in other cases it is auto-incremented and obtains IDs for that moment. Therefore, the time on the ID cannot mostly represent real time. Slow consumption may always lag behind real time. Fast consumption may always far exceed real time (allows pre-borrowing future time, because when filling, lastSecond is directly incremented).
3.7 JD Memory Segment: Segment Mode Based on Redis + Memory Auto-Increment
Looking at short code ID distribution from JD short link design, similar to Leaf Segment, obtaining segments through Redis cache, obtaining IDs through memory auto-increment.
Can utilize dual Buffer optimization, and Redis's own INCRBY atomic increment.
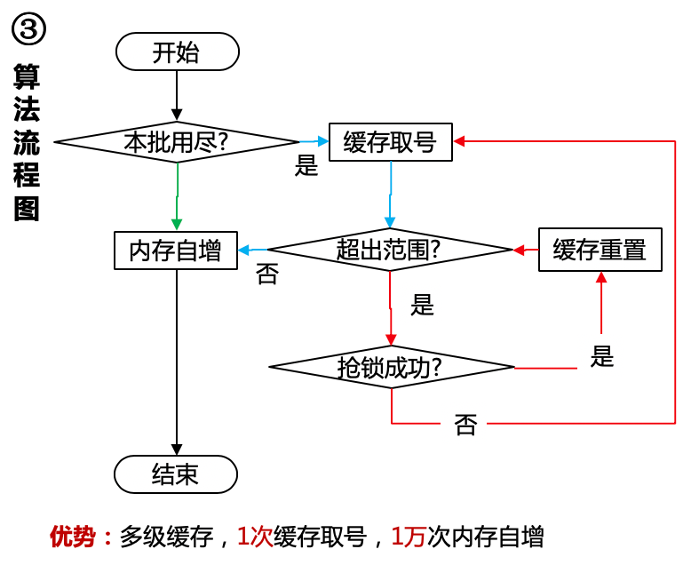
JD Memory Segment Design Overview|500