0. Step Why We Need RAG
When we press Enter in ChatBox and send a request "Can excess credits from core general education courses at the University of Electronic Science and Technology of China be converted to elective credits?", it is predictable that we won't get an effective conclusion: in ChatGPT Web, GPT 5.2 Thinking retrieves relevant school documents and campus forum posts through powerful search capabilities and finally concludes "No"; DeepSeek in ChatBox answers randomly
Another example, asking AI "The original sentence or paragraph where the Bodhisattva tells Sun Wukong that someone will save him, with the chapter title indicated", a very specific question: in ChatGPT Web, thinking for more than 2 minutes, checking 106 web pages, answering irrelevantly, seemingly not understanding the question
The answer we want should be from "Chapter 8: The Buddha Creates Scriptures to Transmit to Paradise; Guanyin Receives Orders to Go to Chang'an": "When the Bodhisattva heard these words, she was filled with joy. She said to the Great Sage: "The scriptures say: 'If the words spoken are good, then they will be answered from thousands of miles away; if the words spoken are not good, then they will be violated from thousands of miles away.' Since you have this intention, when I arrive in the Eastern Land of the Great Tang to find a scripture-seeker, I will teach him to save you. You can become his disciple, uphold the teachings, enter my Buddhist school, and cultivate the true fruit again, how about that?" The Great Sage said repeatedly: "I wish to go! I wish to go!""
Books like Journey to the West are mostly used as training data, but even so, they cannot provide accurate information, and if using web search, it may not necessarily handle factual answers well
The introduction of RAG can help solve such problems:
Lack of domain knowledge or private knowledge, some professional knowledge not being trained, or belonging to internal knowledge bases that the model cannot access
Knowledge has a cutoff date, unable to obtain the latest knowledge
We only need the school's official training manual to provide credit-related knowledge; we only need the complete novel to provide semantically similar paragraphs
1. Intro What is RAG
RAG, short for Retrieval-Augmented Generation, is a technology that combines information retrieval and LLM. It retrieves relevant information from knowledge bases, such as internal documents, databases, etc., to "augment" the LLM's generation capability, making its answers more accurate, real-time, and relevant to specific domains or private data, without retraining the entire model, effectively solving the large model's knowledge limitations and "hallucination" problems
As the name suggests, it is also divided into three stages: Retrieval, Augmentation, and Generation
Retrieval: When a user asks a question, the system searches for relevant information fragments in the knowledge base
Augmentation: Combining the retrieved relevant information with the user's original query to form an augmented Prompt
Generation: Feeding this augmented input prompt to the LLM to generate more accurate and evidence-based answers
2. Simple RAG
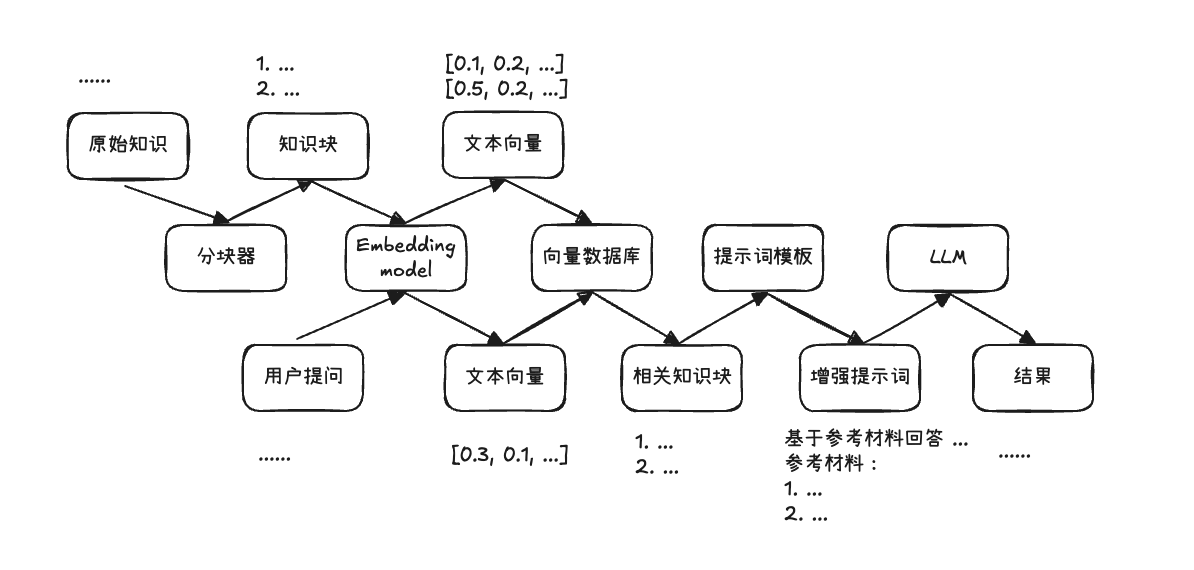
Screenshot 2025-12-28 13.43.06.png|500
As shown in the figure, this is the most basic RAG workflow
Divided into three major stages:
Indexing phase: chunking raw knowledge documents and converting them into vector format
Retrieval phase: converting user queries into vector format and querying the most relevant document knowledge chunks
Generation phase: producing "accurate" answers based on retrieved information
2.1 Indexing Phase
The indexing phase is responsible for chunking raw knowledge documents into knowledge chunks and converting them into vector format through the Embedding model, storing them in a vector database for retrieval
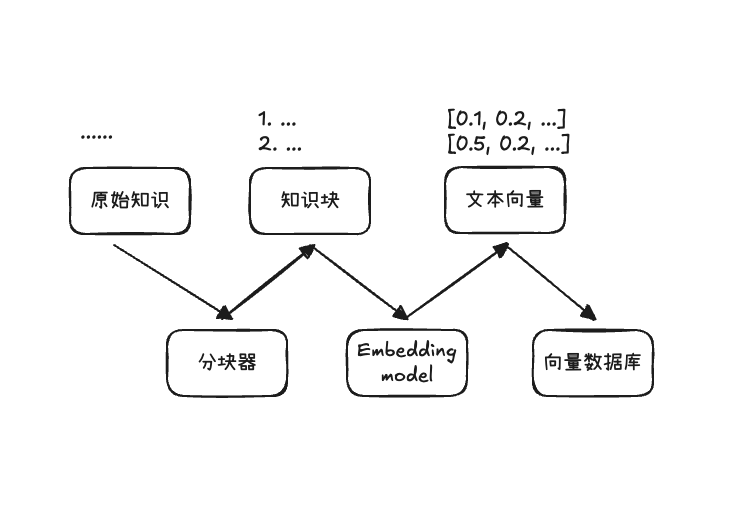
Screenshot 2025-12-28 13.49.20.png|500
2.1.1 Document Chunking
Document chunking is responsible for cutting raw knowledge documents into text knowledge chunks through different chunking strategies
The core requirement is semantic coherence
There are the following chunking schemes:
- Chunk by fixed character count or Token count
- Chunk by punctuation marks
- Chunk by sentences
- Chunk by paragraphs
- Chunk by semantics
- Overlapping chunking
In short, there are various methods, mainly depending on the document type, appropriately chunking it into small pieces to ensure semantic coherence
2.1.2 Text Vectorization
The purpose of text vectorization Embedding is to convert the chunked text chunks into numerical representations that computers can easily calculate, i.e., vectors
Naive methods include: deduplicated bag-of-words, non-deduplicated bag-of-words, TF-IDF
The bag-of-words method first extracts tokens from the corpus, treating each token as a dimension
Deduplicated bag-of-words: if the token exists in the text, the corresponding dimension is marked as 1, otherwise 0
Non-deduplicated bag-of-words: each token's corresponding dimension records the number of times the token appears in the text
TF-IDF: On the basis of word frequency, introduces inverse document frequency weighting. Common but low-distinction words are down-weighted, while words that better reflect text differences are given higher weights
But in any case, they utilize dimensions too sparsely. For a novel, there may be hundreds of thousands of tokens, meaning a vector may have hundreds of thousands of dimensions, but for a specific knowledge chunk, most dimensions are 0 with only a few having values. Thus, dense vectors were developed
Dense vectors, i.e., the Embedding models we now use, compress the meaning of text into a fixed-dimensional numerical space. Each dimension does not correspond to a specific token but uses lower dimensions to express semantic features. It can capture that happy and glad are synonyms, and knows the relationship between Beijing and China, Paris and France
In our usage, we only need to input text into the Embedding model to get the corresponding text vector
You can choose appropriate models on HuggingFace's leaderboard, such as
Qwen3-Embedding-8B
gemini-embedding-001
2.1.3 Vector Storage
After obtaining text vectors, we need a place to store them and corresponding retrieval methods. We usually use vector databases to store these vectors
Vector databases support storing vectors and provide similarity-based vector retrieval capabilities, such as TopK nearest neighbor queries, used to quickly find content most relevant to the query from massive chunks
Generally, three types of information are saved in vector databases:
- Vector itself: the embedding vector of the chunk
- Original content: the chunk for direct concatenation in augmented prompts
- Metadata: storing source documents, chapters, directories, page numbers, offsets, timestamps, etc.
Vector databases are quite diverse; you can search and use them yourself, such as:
Chroma
Qdrant
2.2 Retrieval Phase
The retrieval phase is responsible for converting user queries into text vectors and querying the most relevant document knowledge chunks
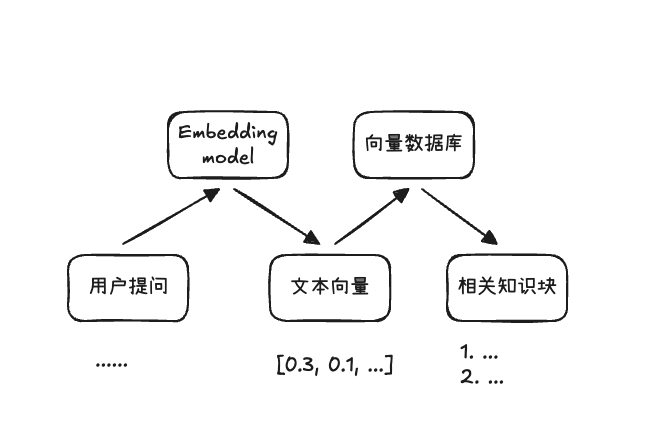
Screenshot 2025-12-28 14.33.51.png|500
Since we have encoded text semantics into vectors, the core of retrieving based on text similarity is to see how close two vectors are. Common methods mainly include: cosine similarity, Euclidean distance, inner product
Cosine similarity focuses on whether the directions of two vectors are consistent, i.e., their cosine value, with a range of [-1, 1]. The closer to 1, the more consistent the direction
Euclidean distance focuses on the straight-line distance between two vectors in space. The smaller the distance, the closer they are
Inner product is affected by both direction and length. The more consistent the direction and the longer the length, the larger the inner product tends to be
In addition, there is keyword-based retrieval, i.e., extracting keywords from user queries to match corresponding documents, which is more effective in some scenarios, but not introduced in detail here
2.3 Generation Phase
The generation phase is responsible for concatenating the information retrieved in the previous step with the user query to form an augmented prompt Augmented Prompt and handing it to the LLM, allowing it to produce "accurate" answers with evidence
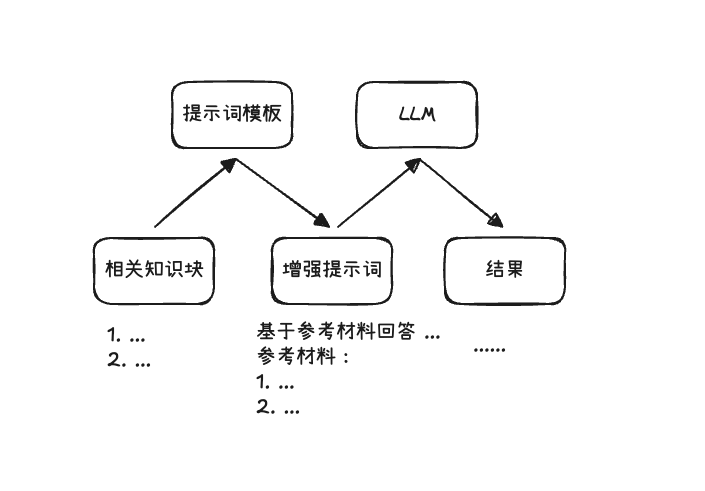
Screenshot 2025-12-28 14.46.43.png|500
There is not much to say about this stage; it mainly involves selecting and organizing context, i.e., concatenating the retrieved chunks with user queries, and finally handing them to the LLM
However, it also involves some optimizations, such as:
- Obtaining different topK chunks results through various retrieval methods, how to filter more appropriate topK chunks
- How to make prompt templates clearer and more explicit
- How to make the LLM correctly cite relevant evidence when generating answers
2.4 Practical Implementation
The theoretical part of Simple RAG is finished. Next, we implement a simple novel Q&A RAG, using the Journey to the West question we introduced at the beginning as a case study
I used LM Studio locally to run Embedding and LLM services, which can provide OpenAI Compatible format API interfaces
I used text-embedding-qwen3-embedding-0.6b and qwen/qwen3-4b-2507 as the models for this practical implementation
Install the following dependencies: pip install openai chromadb
Where chromadb is an open-source vector database, openai is added for convenient API usage
Indexing Phase
For chunking, first divide chapters according to the title format "Chapter xx", then use overlapping chunking for each chapter, chunking by CHUNK_SIZE, but the starting point moves forward by OVERLAP each time. That is, if a chapter has 2500 characters, then the chunks are: [0, 800), [650, 1450), [1300, 2100), [1950, 2750), [2600, none), the last empty block will be filtered out
Then vectorize each chunk and add it to the vector database. meta_data can include chapter titles
Distance metrics include: cosine, l2, ip (cosine similarity, Euclidean distance, inner product)
Here we choose cosine similarity; chromadb must set the metric when creating the collection
Retrieval Phase
Vectorize the user query and find the topK most similar results in the vector database
Generation Phase
Concatenate user messages and retrieved results context to form an augmented prompt, and hand it to the LLM to generate answers
CodeBlock Loading...
I tested the answers with topK set to 1, 2, and 3 respectively. They were basically usable. Actually, the correct original text paragraph was top1. In the top2 case, the model probably didn't understand what "someone will save him" meant. Using the deepseek-chat API gave answers that met my expectations
top2 case
The original sentence where the Bodhisattva tells Sun Wukong that someone will save him is: "I was ordered by the Buddha to go to the Eastern Land to find a scripture-seeker, and passing by here, I specially stopped to see you."
Source: Chapter 8: The Buddha Creates Scriptures to Transmit to Paradise; Guanyin Receives Orders to Go to Chang'an
[References]
Chapter 8: The Buddha Creates Scriptures to Transmit to Paradise; Guanyin Receives Orders to Go to Chang'an (Similarity: 70.0%)
Chapter 14: The Mind-Monkey Returns to the Right; The Six Thieves Vanish Without Trace (Similarity: 69.9%)
top3 case
The original sentence where the Bodhisattva tells Sun Wukong that someone will save him is: "Since you have this intention, when I arrive in the Eastern Land of the Great Tang to find a scripture-seeker, I will teach him to save you. You can become his disciple, uphold the teachings, enter my Buddhist school, and cultivate the true fruit again, how about that?"
Chapter title: Chapter 8: The Buddha Creates Scriptures to Transmit to Paradise; Guanyin Receives Orders to Go to Chang'an
[References]
Chapter 8: The Buddha Creates Scriptures to Transmit to Paradise; Guanyin Receives Orders to Go to Chang'an (Similarity: 70.0%)
Chapter 14: The Mind-Monkey Returns to the Right; The Six Thieves Vanish Without Trace (Similarity: 69.9%)
Chapter 21: The Dharma-Protector Sets Up a Manor to Keep the Great Sage; Sumeru's Lingji Settles the Wind Demon (Similarity: 69.9%)
The similarity here is because ChromaDB returns 1 - similarity for cosine distance, so this is just restoring it.
2.5 Summary
At this point, we have successfully run through the simple RAG workflow: offline indexing (chunking, vectorization, storage) + online Q&A (retrieval, augmented prompt, generation)
Meanwhile, through a series of practices, we can also see many shortcomings. In fact, there are many areas for improvement, which is what "Advanced RAG" aims to solve
- Chunking: How to chunk to ensure semantic coherence (semantic chunking)
- Retrieval: How to improve retrieval precision and recall (multi-way recall, Rerank, etc.)
- Query: Making the query used for matching clearer and more retrievable (query rewriting, coreference resolution)
- Generation: How to write prompts and organize context (prompt templates, citations)
- Evaluation: How to evaluate RAG with metrics (precision, recall, faithfulness)