一、场景引入
场景 - URL 去重过滤在亿级数据量下的解决方案
以大规模网页爬虫为例,在针对特定关键词的大规模网页爬虫中,待抓取的 URL 数量可能达到数亿,重复 URL 不仅浪费爬取资源,还可能导致爬虫陷入死循环或无效抓取,严重影响抓取效率和数据质量
传统的方案
- 存入数据库,添加约束 unique
- I/O 瓶颈
- 使用缓存,例如 HashSet
- 内存开销大
方案优化
考虑到 URL 爬虫去重允许误判,大数据量的情况下小部分数据误判完全允许
- 使用位图,单哈希压缩存储,利用二进制数组记录 URL 是否出现,内存空间占用更小
- 百亿 URL 内存占用估算,$1%n=10^{10}$, 位图大小 ,占用
- 进一步优化位图,即布隆过滤器,利用多个($k$ 个)哈希函数,将每个元素映射到二进制数组的多个($k$ 个)bit 上,用多个 bit 代表一个元素
二、布隆过滤器简介
概念
布隆过滤器(Bloom Filter)是一种基于位图(Bit Array)的概率型数据结构,它能够高效地检测一个元素"可能存在"或者"绝对不存在"。
- 空间效率高:利用位数组保存数据,极大地节省了空间。
- 查询速度快:插入和查询操作都是常数级别的时间复杂度 ,其中 是哈希函数的数量。
- 可能误判:存在误判的可能性,即可能误认为某个未插入的元素存在于集合中(假阳性,False Positive),但绝不会误判元素不存在。
示意图
初始化布隆过滤器
image.png|500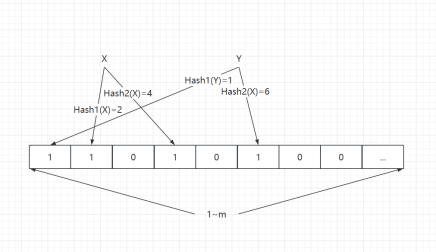
image.png|500
查询:绝对不存在及可能存在
绝对不存在:查询并插入 Z
Z 在查询时发现只有一个 bit 是 1,另一位 bit 是 0,可证明绝对不存在
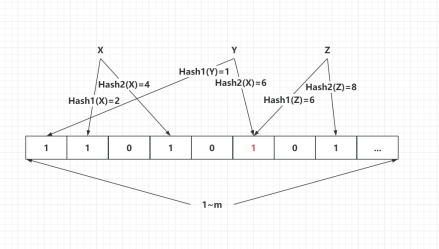
image.png|500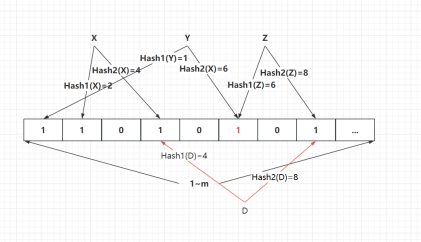
image.png|500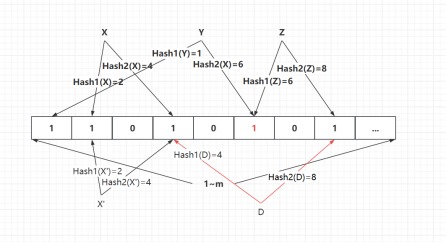
image.png|500
参数
参数含义
- 待插入元素个数
- 位数组长度
- 哈希函数个数
- 误判率
推导公式
- 插入 个元素 次哈希后某一 bit 位仍为 的概率
- 插入 个元素 次哈希后某一 bit 位仍为 的概率
- 插入 个元素 次哈希后某一 bit 位被置为 的概率
- 插入 个元素 次哈希得到的 bit 位均已被置为 的概率
- 可推导出误判率
参数预估 已知待插入数 及 误判率
- 位数组长度
- 哈希函数个数
特征
增、查,无删 很明显布隆过滤器无法支持删除操作,因为多个元素可能哈希到一个布隆过滤器的同一个位置,参考上方布隆过滤器示意图
占用空间 百亿 URL 内存占用估算,$1%$ 的假阳率
- 对于位图:长度 ,占用
- 对于布隆过滤器:位数组长度 ,占用约
三、布隆过滤器实战——使用Guava库
实际项目中通常使用 Google 提供的 Guava 库中的布隆过滤器 Guava 的 Maven 仓库
小案例
引入 Guava 依赖
<!-- https://mvnrepository.com/artifact/com.google.guava/guava -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>32.1.2-jre</version>
</dependency>
Guava 库的布隆过滤器核心方法
put():插入元素mightContain():判断元素是否可能存在
示例案例
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class BloomFilterExample
{
private static Integer expectedInsertions = 10000000;
private static Double fpp = 0.01;
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), expectedInsertions, fpp);
public static void main(String[] args)
{
for (int i = 0; i < expectedInsertions; i++)
{
bloomFilter.put(i);
}
int count = 0;
for (int i = expectedInsertions; i < expectedInsertions * 2; i++)
{
if (bloomFilter.mightContain(i))
{
count++;
}
}
System.out.println("一共误判了:" + count);
}
}
插入 的数据,判断 个数据,误判 次
四、Guava BloomFilter 源码深入分析
BloomFilter类
封装了布隆过滤器的核心逻辑,如添加、查询元素、初始化参数计算(如位图大小、哈希函数数量)等
- create(Funnel, int, double) 轻用户接口
- create(Funnel, long, double) 高级接口
- create(funnel, expectedInsertions, fpp, Strategy) 核心实现
工厂创建 BloomFilter
public static <T extends @Nullable Object> BloomFilter<T> create(
Funnel<? super T> funnel, int expectedInsertions, double fpp) {
return create(funnel, (long) expectedInsertions, fpp);
}
public static <T extends @Nullable Object> BloomFilter<T> create(
Funnel<? super T> funnel, long expectedInsertions, double fpp) {
return create(funnel, expectedInsertions, fpp, BloomFilterStrategies.MURMUR128_MITZ_64);
}
核心方法
public boolean put(@ParametricNullness T object) {
return strategy.put(object, funnel, numHashFunctions, bits);
}
public boolean mightContain(@ParametricNullness T object) {
return strategy.mightContain(object, funnel, numHashFunctions, bits);
}
static int optimalNumOfHashFunctions(long n, long m) {
// (m / n) * log(2), but avoid truncation due to division!
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
static long optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
Funnel 接口
Funnel 接口的主要职责是将一个对象的状态“注入”到一个 PrimitiveSink 中,从而产生连续的字节序列,如此才可以对自定义结构使用布隆过滤器
public interface Funnel<T> {
void funnel(T from, PrimitiveSink into);
}
- T from:需要转换的对象。
- PrimitiveSink into:接收对象数据的容器。PrimitiveSink 提供了多种方法,可以将基本数据类型和字符串写入到一个统一的字节流中
Guava 自带有原生 Funnel,如 integerFunnel()、stringFunnel(Charset)、byteArrayFunnel() 等
案例
Goods
@Data
@AllArgsConstructor
public class Goods {
private final int id;
private final String name;
}
PojoBloomFilter
public static void main(String[] args)
{
// 预计插入10000个Person对象,误判率设为0.01
BloomFilter<Goods> personBloomFilter = BloomFilter.create(
PersonFunnel.INSTANCE,
10000,
0.01
);
// 创建并插入一个Goods对象
Goods apple = new Goods(1, "apple");
personBloomFilter.put(apple);
// 查询某个对象是否可能存在
Goods queryGoods1 = new Goods(1, "apple");
if (personBloomFilter.mightContain(queryGoods1))
{
System.out.println(queryGoods1 + "可能存在于布隆过滤器中");
}
else
{
System.out.println(queryGoods1 + "肯定不存在于布隆过滤器中");
}
Goods queryGoods2 = new Goods(2, "banana");
if (personBloomFilter.mightContain(queryGoods2))
{
System.out.println(queryGoods2 + "可能存在于布隆过滤器中");
}
else
{
System.out.println(queryGoods2 + "肯定不存在于布隆过滤器中");
}
}
Funnel 作用
- 保证一致性 Funnel 保证了只要是同一种结构,哈希前的预处理就一致
- 控制粒度 自定义的类,如果想用布隆过滤器,可以自选字段注入,如 Goods 注入 id、name
Strategy 接口(默认实现:MURMUR128MITZ64)
Strategy 接口定义了布隆过滤器的哈希策略、元素插入以及查询具体操作 默认使用 MURMUR128MITZ64
- MURMUR128:MurmurHash3 128 位变种
- MITZ:源自 Google 的工程师 Mitz Pettel,设计了下述“双重哈希”技巧
- 64:每次使用 64 位
可以发现并没有真的使用 个哈希函数,并且实现中使用了一次 Hash,并分割成两个字段 《Less Hashing, Same Performance: Building a Better Bloom Filter》提出优化算法,只需计算两个独立哈希函数即可构造出等价于使用多个哈希函数的布隆过滤器 $$gi(x)=h1(x)+i·h_2(x)$$
public <T extends @Nullable Object> boolean put(
@ParametricNullness T object,
Funnel<? super T> funnel,
int numHashFunctions,
LockFreeBitArray bits) {
long bitSize = bits.bitSize();
byte[] bytes = Hashing.murmur3_128().hashObject(object, funnel).getBytesInternal();
long hash1 = lowerEight(bytes);
long hash2 = upperEight(bytes);
boolean bitsChanged = false;
long combinedHash = hash1;
for (int i = 0; i < numHashFunctions; i++) {
// Make the combined hash positive and indexable
bitsChanged |= bits.set((combinedHash & Long.MAX_VALUE) % bitSize);
combinedHash += hash2;
}
return bitsChanged;
}
策略传入 BitArray 的 index = (combinedHash & Long.MAX_VALUE) % bitSize),目的是让 combinedHash 为正,否则无法对 bitSize 取模(负索引异常)
BitArray 模块
BitArray 是布隆过滤器底层实现的核心,负责位数组的存储与管理
static final class LockFreeBitArray {
private static final int LONG_ADDRESSABLE_BITS = 6;
final AtomicLongArray data;
private final LongAddable bitCount;
LockFreeBitArray(long bits) {
checkArgument(bits > 0, "data length is zero!");
// Avoid delegating to this(long[]), since AtomicLongArray(long[]) will clone its input and
// thus double memory usage.
this.data = new AtomicLongArray(Ints.checkedCast(LongMath.divide(bits, 64, RoundingMode.CEILING)));
this.bitCount = LongAddables.create();
}
boolean set(long bitIndex) {
if (get(bitIndex)) {
return false;
}
int longIndex = (int) (bitIndex >>> LONG_ADDRESSABLE_BITS);
long mask = 1L << bitIndex; // only cares about low 6 bits of bitIndex
long oldValue;
long newValue;
do {
oldValue = data.get(longIndex);
newValue = oldValue | mask;
if (oldValue == newValue) {
return false;
}
} while (!data.compareAndSet(longIndex, oldValue, newValue));
// We turned the bit on, so increment bitCount.
bitCount.increment();
return true;
}
boolean get(long bitIndex) {
return (data.get((int) (bitIndex >>> LONG_ADDRESSABLE_BITS)) & (1L << bitIndex)) != 0;
}
}
- 使用 long(64 bit) 数组
- bitCount 被置为 的 bits 数,利用原生方法 Long.bitCount() 统计负载程度
- get 方法 index 逻辑右移得 long 元素索引,index 利用 AND 得取模后的具体索引
- set 方法 利用 compareAndSet 原子更新
- putAll 方法 利用 OR 操作两个 BitArray,用于布隆过滤器的合并
五、布隆过滤器的衍生技术
计数布隆过滤器 Counting BloomFilter
- 在普通布隆过滤器基础上允许删除操作
- 通过位计数方式进行
- 缺点是空间占用较大
Bloomfilter
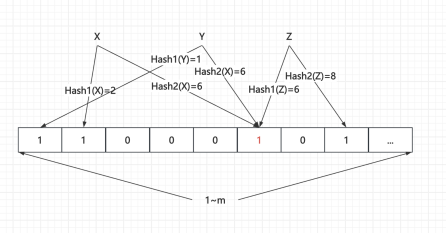
image.png|500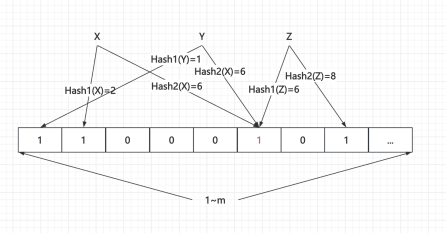
image.png|500
定时重构布隆过滤器
- 周期性重构
- 删除旧布隆过滤器
- 重构新布隆过滤器
六、实际场景
大数据量的商品 id
- 用户请求一个商品
- 与爬虫过滤 URL 不同,不可失误
- 使用数据库?
- 使用缓存?
- 使用布隆过滤器?
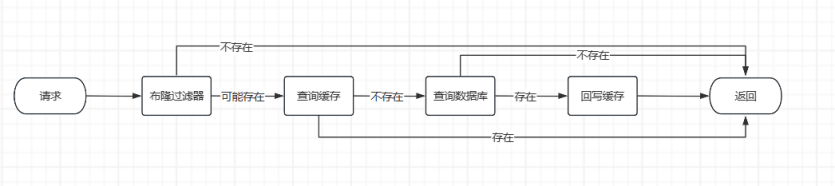
image.png|700