1. 绪论
在高吞吐量的系统中,例如促销期间的电商平台,为每笔订单快速分配一个全局唯一且不冲突的编号至关重要
如果只凭借数据库自增 ID,那么吞吐量一大,数据库就成了系统当中的瓶颈; 而在多实例部署的情况下,无法保证各节点生成的 ID 全局唯一、不会冲突; 以及完全随机生成的乱序 ID 可能导致数据库索引频繁页分裂; 还有可能会因为 ID 暴露系统的隐私信息,比如业务量
这就是分布式 ID 需要解决的:全局唯一、高可用高性能、趋势递增、安全
于是涌现了许多方案:划分 bit 位的雪花算法、批量产生 ID 的号段模式、纯本地生成的 UUID...
2. ID 形态:四类分布式 ID 主要形态与特点
ID 形态大致有四种:
时间序列类:SnowFlake、UUID v1/v6/v7
他们用时间戳作为高位,拼接随机数、序列号、节点号,保证了时间上的有序
优点:时间有序、本地生成
缺点:时钟回拨、泄露时间
随机类:UUID v4 不依赖时间、不依赖机器,完全随机 优点:随机、不会暴露信息、本地生成 缺点:无序,对索引不友好
号段分发类:DB、Leaf Segment、TinyID、Redis 一次取一批号码(号段)到内存,在本地自增发号 优点:易扩展、趋势有序、通过双 Buffer 优化更加平滑稳定 缺点:泄露业务量、依赖 DB 或 Redis 维护分配量、为水平扩展只能保证趋势有序
环形缓冲预填充类:uID-generator 参考了号段和雪花算法,利用雪花算法的位分配思想构建有序 ID,并填充一个环形数组作为缓存池,其时间戳只在初始化时设置,后续只在填充缓存时自增并获取那一时刻的全部 ID 优点:有序、本地生成、可突破 1s 的序列号上限,实现高并发 缺点:ID 中的时间戳无法代表真实时间,但可以预借未来时间
3. 具体实现:七种分布式 ID 生成方案解析
3.1 SnowFlake:Twitter 开源的位划分时间序列 ID 方案
雪花算法是 Twitter 开源的一种分布式 ID 生成算法,核心就是划分空间,分别标识
结构与位分配

SnowFlake 算法的位分配结构示意图|500
41 位的时间戳是毫秒级别的,可以容纳 大概 69 年的时间,将时间戳放在高位可以保证分布式生成的 ID 总体上来看是递增的
两个 5 位的标识位可以提供 个机器 ID,12 位自增序列号可以表示 个 ID
那么理论上来说,一台机器使用雪花算法获取 ID 的 IDs/s 为
问题
强依赖时间,如果出现时钟回拨现象会导致 ID 异常,比如重复、逆序等问题
时钟回拨
- 直接阻塞至 lastTimestamp
- 维护一个在回拨时增长的 offset,实际使用 logicalTimestamp=currentTimestamp+offset
- 借高位作为回拨 tag
3.2 数据库生成:基于数据库自增的 ID 方案
利用数据库 auto-increment 生成自增 ID,通过给不同的机器设置不同的初始值以及相同的等于机器数的步长
缺陷
强依赖 DB,不容易扩展,因为步长采用机器数 如果是单机 DB,则限制了发号上限,如果是多机,那么只能保证趋势递增,并且维护困难 DB 压力大,因为每次获取 ID 都要读写
3.3 UUID 系列:通用唯一标识符
UUID(Universally Unique IDentifier) 通用唯一标识符,也叫 GUID,由 32 个 16 进制数字组成,形式为 xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx,其中 M 和 N 分别代表版本和变体
UUID v1
60bit 时间戳 + 14bit 时钟序列 + 48bit 节点(常见为 MAC 或伪随机)
v1 的 60bit 时间戳(单位 100ns,自 1582-10-15 起)被切分为 time_low(32) + time_mID(16) + time_high(12)
UUID v4
除版本/变体位外几乎全随机(122bit 熵) 不暴露时间或主机信息 JDK 的 UUID.randomUUID() 就是 v4 版本
UUID v6
v1 的重排版本,按高位时间有序排序,更加适宜数据库插入
60bit 时间戳 + 14bit 时钟序列 + 48bit 节点(常见为 MAC 或伪随机)
60bit 时间戳划分 time_high(32)+time_mID(16)+time_low(12)
UUID v7
48bit 毫秒级别时间戳+ 12bit randa + variant + randb(其余随机/单调字段)
UUID v7 吸收了 ULID 的理念
ULID 通用唯一可字典序排序标识符
48 bits │ 80 bits 48 bit 毫秒级时间戳 80 bit 安全随机数
值得注意的就是 ULID 采用了 Base32 编码(数字 + 字母,删去
I,L,O,U),不同于 UUID 的 Base16 编码,最终表现为 26 位字符串,如01FZ4Q3YSJH9X8HRXW4E7JKX4N
3.4 美团 Leaf:高可用分布式 ID 生成服务
美团技术: Leaf——美团点评分布式ID生成系统(https://tech.meituan.com/2017/04/21/mt-leaf.html?utm_source=chatgpt.com)
Leaf Segment
在数据库的方案上优化,原方案是一个号码就会请求一次数据库,现在优化成用一个 proxy server 批量获取,每次获取到一个号段 segment 的号码,用完后再批量获取一个号段
| Field | Type | Null | Key | Default | Extra | Comment |
|---|---|---|---|---|---|---|
| biz_tag | varchar(64) | NO | Primary | NULL | 业务标识(如 `order_tag) | |
| max_ID | bigint unsigned | NO | 0 | 已分配到的最大ID | ||
| step | int unsigned | NO | 1000 | 号段大小(每次批量步长) | ||
| desc | varchar(255) | YES | NULL | |||
| update_time | timestamp | NO | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP |
用 biz_tag 区分业务,每次获取 step 个号码,对数据库的读写频率从 1 降低到了 1/step 次
优点
- ID 是趋势自增的
- 可以线性扩展
缺点
- ID 是自增的,不够随机,会泄露信息
- 在耗尽号码后再次批量获取时会有一个大的抖动
双 Buffer 优化
在这个方案中整个取码看起来并不是平稳的,在耗尽号段,取号段时取码会有一次大的波动,而为了实现无阻塞的取码,可以考虑在号段使用到一个阈值时异步取下一个号段,而不是等耗尽号段后,在取码时阻塞着获取新号段
也就是两个号段 buffer,当当前使用的号段达到某个阈值,就异步获取下一个号段,当当前的号段耗尽直接切换到另一个号段发号,实现稳定的发号
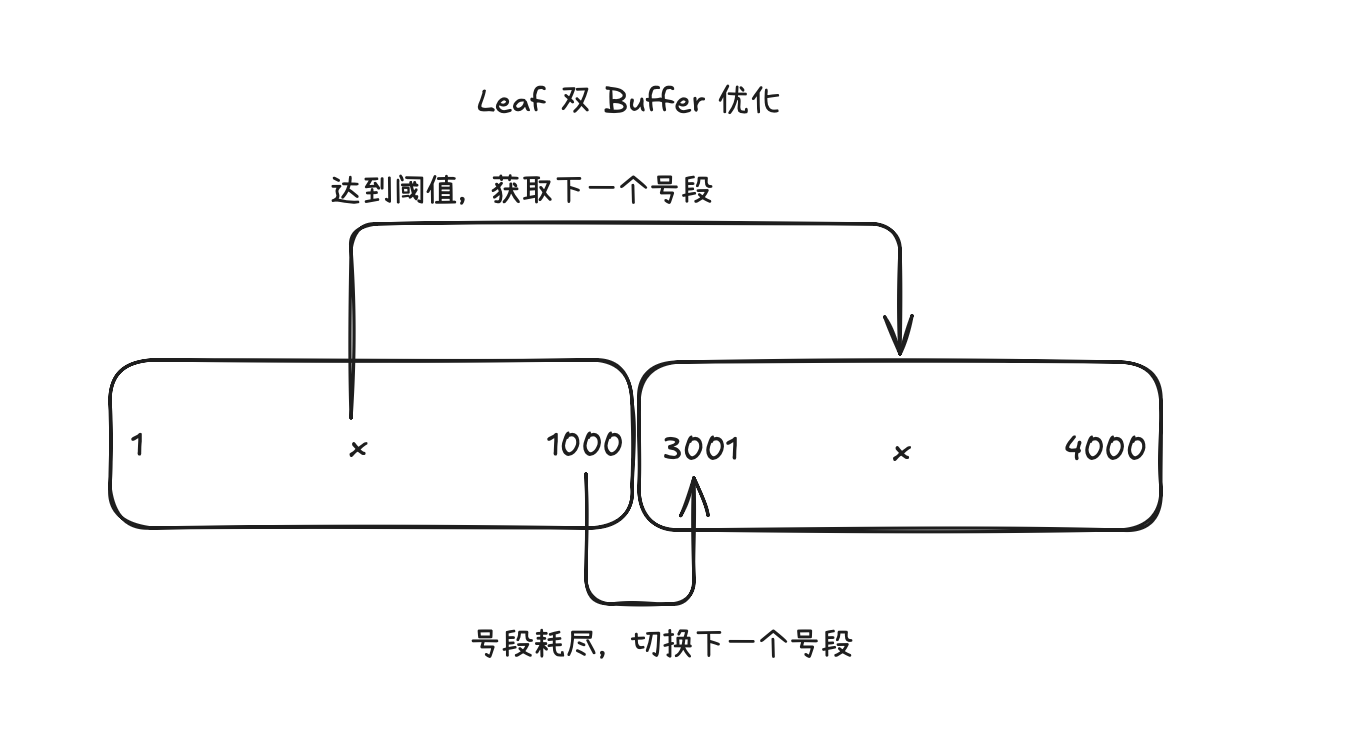
美团 Leaf 双 Buffer 优化原理图|500
Leaf SnowFlake
Leaf Segment 方案可以稳定获取趋势递增的 ID,但是会泄漏数据量,所以有了 Leaf SnowFlake 方案
仍然沿用 SnowFlake 的划分 bit 设计
位分配 1 | 41 | 10 | 12 1bit 空置 41bit 毫秒级别时间戳 10bit workerID 12bit 序列号,每毫秒内 0~4095
时钟回拨
用 ZooKeeper 做时间一致性与健康探测
/leaf_forever/{self}:持久节点,存储该实例最近一次上报的系统时间(毫秒),用于启动与运行期比对是否发生大步长回拨/leaf_temporary/{self}:临时节点,运行期定时(如每 3s)上报本机时间,同时拉取所有在线节点时间,计算均值或中位数
3.5 滴滴 TinyID:支持多 Master DB 的号段模式
在原理上和 Leaf Segment 差不多,也利用了双 Buffer 缓冲,但是还支持了多 master db,即使号段相同也没有交集,ID % delta == remainder
| ID | biz_type | max_ID | step | delta | remainder | version |
|---|---|---|---|---|---|---|
| 1 | order | 10000 | 1000 | 3 | 0 | 0 |
| 2 | order | 10000 | 1000 | 3 | 1 | 0 |
| 3 | order | 10000 | 1000 | 3 | 2 | 0 |
biz_type 业务 ID
max_ID 支持多最大 ID
step 步长,即一个号段的大小
delta ID 每次的增量,支持多 db 所用
remainder 余数,支持多 db 所用
举例
A B C 3 个 master db
都可以拿到 (3000,4000] 这个号段,但是每个段都先对齐自己的 first
first = start + ((end - start % delta + delta) % delta)
也就是每个 db 的号段只能提供 1/delta 的部分
也可以实现如只有单数的 ID,即 delta = 2, remainder = 1
3.6 百度 uID generator:基于双 RingBuffer 优化、可预填充的雪花算法
位分配

百度 uID-generator 位分配结构|500
1 | 28 | 22 | 13 1bit 空置 28bit 秒级别时间戳 22bit workerID 13bit 序列号,每秒内 0~8191
DefaultUIDGenerator 即普通的 SnowFlake
synchronized
获取当前时间
当前时间小于上次时间
抛异常,时钟回拨
当前时间等于上次时间
序列号自增,同时取模最大序列号(也就是 & 8191)
序列号等于 0(也就是超过当前秒所能供应的上限)
阻塞至下一秒并修改当前时间
当前时间是最新的
序列号置为 0
上次时间置为当前时间
构造 ID
CachedUIDGenerator 采用了双 RingBuffer,UID-RingBuffer 用于存储 UID、Flag-RingBuffer 用于存储 UID 状态(CANTAKE、CANPUT)
RingBuffer 是一个环形数组,使用了 tail 生产者指针、cursor 消费者指针,容量为每秒支持的最大序列号也就是 8192
获取 ID 直接从 RingBuffer 中获取 填充 ID
- 程序启动时:填满 RingBuffer 8192 个 ID
- 在
getUID()时检查容量,如果剩余 ID 小于一定阈值,如 50%,则将其填满 - 定时填满
生成 ID 通过传入的 currentSecond 构建出第一个 ID,随后填满 ID 列表至单秒最大序列号数 填充 ID 通过获取 lastSecond 下一秒的所有 ID,逐个填充,直至 RingBuffer 满了
缺陷 在这个方案中,lastSecond 与现实时间可能不同,除了初始化时设置其为现实时间,其余情况都是自增并获取那一时刻的 IDs,所以 ID 上的时间并不能大部分的代表现实时间 消费的慢很可能一直落后于现实时间 消费的快很可能一直远超于现实时间(允许预借未来时间,因为填充时是直接自增 lastSecond)
3.7 京东内存号段:基于 Redis + 内存自增的号段模式
从京东短链接设计看短码 ID 分发,类似于 Leaf Segment,通过 Redis 缓存获取号段,通过内存自增得到 ID
可以利用双 Buffer 优化,以及 Redis 本身的 INCRBY 原子增加
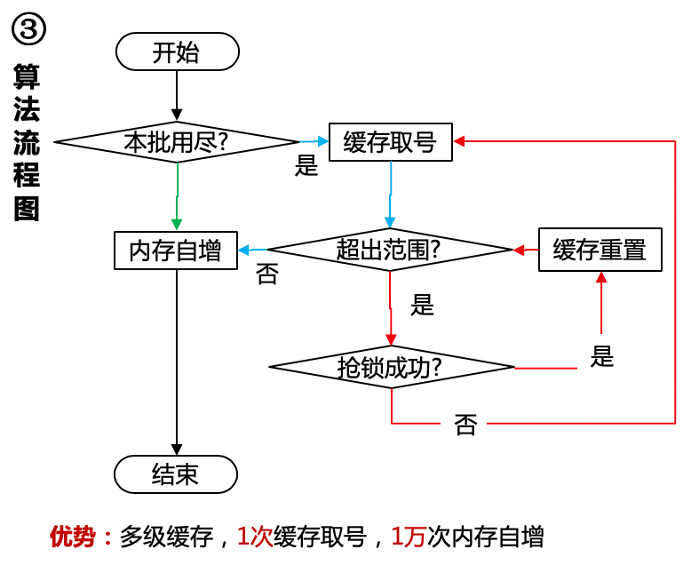
京东内存号段设计概览|500