0. Step 为什么需要 RAG
当我们在 ChatBox 中敲下回车,发送了一条请求「电子科技大学核心通识课程修满溢出的学分可以转换为自主选修学分吗」,可预料到的并不会得到有效结论:在 ChatGPT Web 中,GPT 5.2 Thinking 通过强大的搜索能力检索学校相关文件、校园论坛帖子最终得出「不能」的结论;ChatBox 中的 DeepSeek 直接乱答
再比如,向 AI 提问「菩萨告诉孙悟空有人救他的原文句子或段落,并标注回目」,十分具体的问题:在 ChatGPT Web 中,思考 2 分钟多,查了 106 个网页,答非所问,似乎没理解题意

DeepSeek 回答|500
ChatGPT 回答|500
我们想要的答案应该是《第八回 我佛造经传极乐 观音奉旨上长安》的「那菩萨闻得此言,满心欢喜。对大圣道:“圣经云:‘出其言善,则千里之外应之;出其言不善,则千里之外违之。’你既有此心,待我到了东土大唐国寻一个取经的人来,教他救你。你可跟他做个徒弟,秉教伽持,入我佛门,再修正果,如何?”大圣声声道:“愿去!愿去!”」
像西游记这种书籍大多会被当作训练数据,可即便如此,也不能准确的给出信息,而若是利用网络搜索,也不一定能够处理好事实回答
RAG 的引入能够助力这类问题的解决:
领域知识或私有知识的匮乏,部分专业知识未被训练到,或是属于内部知识库,模型无法获知
知识存在截止日期,无法获取最新知识
我们只需要学校官方的培养手册,就可以提供学分相关的知识;只需要完整的小说,就可以提供语义相近的段落
1. Intro 什么是 RAG
RAG 全称 Retrieval-Augmented Generation 检索增强生成是一种结合信息检索和 LLM 的技术,它通过从知识库,如内部文档、数据库等,中检索相关信息,来“增强”LLM 的生成能力,使其回答更准确、实时、并与特定领域或私有数据相关,而无需重新训练整个模型,有效解决了大模型知识局限和“幻觉”问题
顾名思义,也分成了三个阶段,检索、增强、生成
检索 Retrieval:当用户提出问题时,系统会在知识库中搜索相关的信息片段
增强 Augmentation:将检索到的相关信息与用户的原始语句结合,形成一个增强的提示词 Prompt
生成 Generation:将这个增强的输入提示词交给 LLM,生成更准确、更有依据的回答
2. 简易 RAG
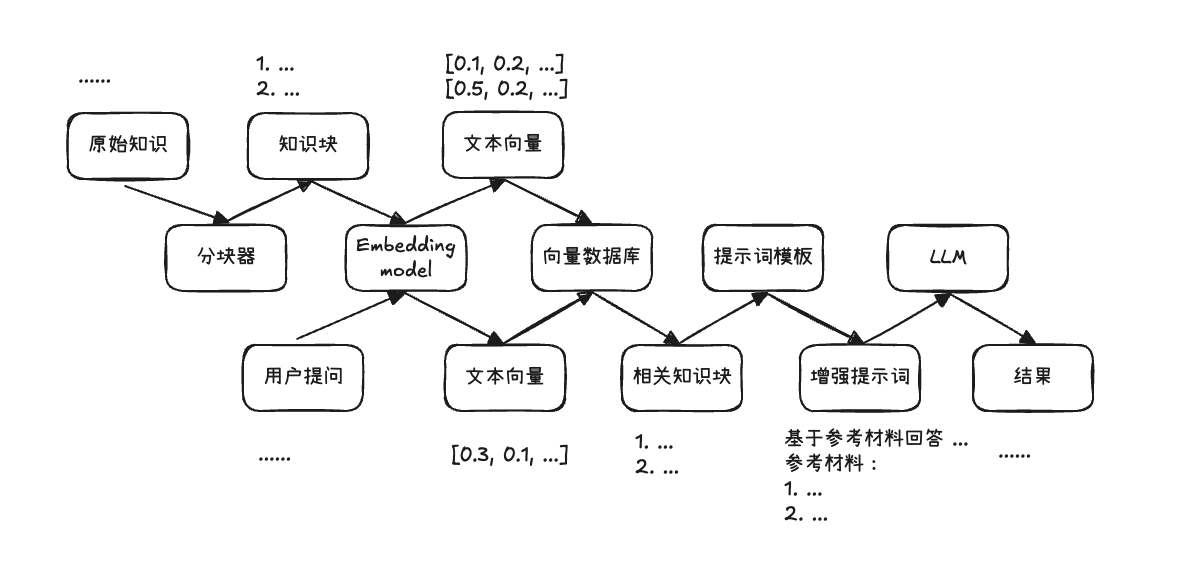
截屏2025-12-28 13.43.06.png|500
如图就是最基本的 RAG 流程
分为三大阶段:
索引阶段,将原始的知识文档切块并转化为向量格式
检索阶段,把用户查询转化为向量格式,并查询与之最相关的文档知识块
生成阶段,基于检索到的信息产生“准确”答案
2.1 索引阶段
索引阶段负责将原始的知识文档 document 切块成知识分块 chunk,并通过 Embedding model,将其转化为向量格式,并存入向量数据库,以供检索
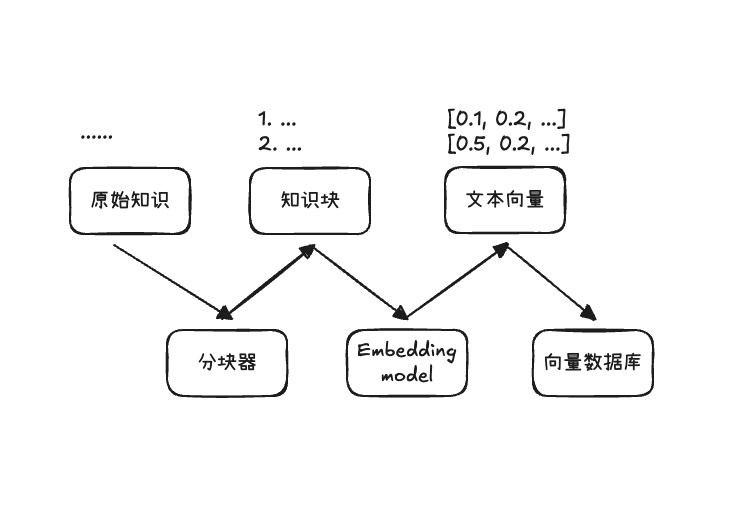
截屏2025-12-28 13.49.20.png|500
2.1.1 切分文档
切分文档负责将原始的知识文档 document 通过不同的切分策略切成一个个文本知识块 chunk
核心的要求就是语义连贯
有如下的切分方案:
- 按照固定的字符数、Token 数切分
- 按照标点符号切分
- 按照句子切分
- 按照段落切分
- 按照语义切分
- 重叠切分
总之多种多样,主要就是根据文档的类型,对其合适地切分成小块,保证语义连贯即可
2.1.2 文本向量化
文本向量化 Embedding 的目的,是把切分后的文本块 chunk 转换为计算机易于计算的数值表示,也就是向量
朴素的方法有:去重词袋法、不去重词袋法、TF-IDF
词袋法会先从语料中提取词元,将每个词元视为一个维度
去重词袋法:如果文本中存在这个词元,那么该词元对应的维度就记为 1 否则为 0
不去重词袋法:每个词元对应的维度记录了该词元在文本当中出现的次数
TF-IDF:在词频的基础上,引入逆文档频率进行加权,常见但区分度低的词会被降低权重,而更能体现文本差异的词会被赋予更高权重
但无论如何,他们对于维度的利用太过稀疏,对于一本小说来说,光词元可能就数十万,也就是一个向量可能有数十万维度,但对于某个知识分块来说,大量的维度都是 0 少部分才有值,于是衍生出了稠密向量
稠密向量,也就是现在我们使用的 Embedding model,将文本的含义压缩到一个固定维度的数值空间当中,每一个维度并不对应具体某个词元,只是用较低的维度去表达语义的特征,它能捕捉到快乐和高兴是同义词,知道北京对于中国、巴黎对于法国这种关系
在我们的使用当中,只需要将文本输入到 Embedding model,就可以得到对应的文本向量
可以在 HuggingFace 上的 leaderboard 选择合适的 model,如
Qwen3-Embedding-8B
gemini-embedding-001
2.1.3 向量存储
得到了文本向量后,还需要有一个地方去存储它们,以及需要对应的检索方法,那我们通常就是使用向量数据库去存储这些向量
向量数据库支持存储向量,并提供基于相似度的向量检索能力,如 TopK 近邻查询,用于从海量 chunk 中快速找到与 query 最相关的内容
一般在向量数据库中会保存三类信息:
- 向量本体 chunk 的 embedding 向量
- 原始内容 chunk 用于在增强提示词中直接拼接使用
- 元数据 metadata 存储来源文档、章节、目录、页码、偏移、时间标签等数据
向量数据库也挺多样,可以自行搜索使用,如:
Chroma
Qdrant
2.2 检索阶段
检索阶段负责把用户查询 query 转化为文本向量,并查询与之最相关的文档知识块 chunk
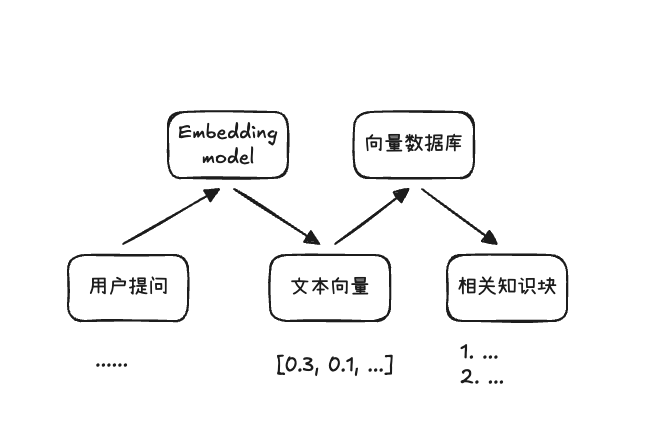
截屏2025-12-28 14.33.51.png|500
既然我们已经将文本语义编码成向量,那么根据文本相似度去检索的核心就是看两个向量有多相近,常见的方法主要是:余弦相似度、欧式距离、内积
余弦相似度关注两个向量的方向是否一致,也就是它们的 cosine 值,[-1,1] 的取值范围,越接近 1 说明方向越一致
欧式距离关注两个向量在空间中的直线距离,距离越小,表示它们越相近
内积同时受到了方向和长度的影响,方向越一致,长度越长,内积往往也就越大
除此之外,还有基于关键词的检索,也就是抽取用户查询 query 中的关键词,然后去匹配对应的文档,部分场景更为有效,但这里不过多介绍
2.3 生成阶段
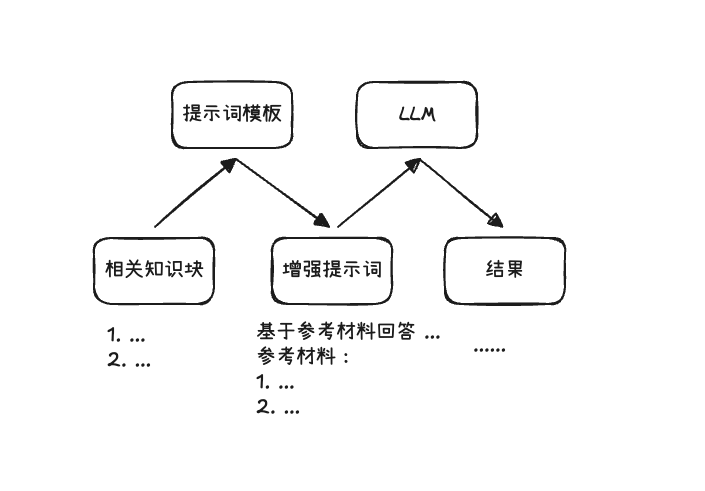
生成阶段负责基于前一步检索到的信息 context 拼接用户查询 query 组合成一个增强提示词 Augmented Prompt 交给 LLM,让其在有依据的情况下产生“准确”答案
截屏2025-12-28 14.46.43.png|500
这一个阶段没什么好说的,主要就是选择并整理上下文,也就是将检索到的 chunks 和用户查询拼接起来,最后交给 LLM
不过也涉及到了一些优化,比如说:
- 通过多种检索方式得到了不同的 topK chunks 结果,如何去筛选更合适的 topK chunks
- 提示词模板怎样更清晰明确
- 如何让 LLM 生成回答的时候,正确的引用相关证据
2.4 实操环节
简易 RAG 的理论环节已经讲完了,接下来我们动手实现一个简易的小说问答 RAG,以我们开始引入的《西游记》提问为案例
我在本地使用 LM Studio 运行了 Embedding 和 LLM 服务,它能提供 OpenAI Compatible 格式的 API 接口
我使用了 text-embedding-qwen3-embedding-0.6b 和 qwen/qwen3-4b-2507 作为本次实操的模型
安装如下依赖 pip install openai chromadb
其中 chromadb 为开源向量数据库 openai 为方便使用接口而添加
索引阶段
对于切块,先用根据标题格式“第 xx 回”划分章节,对于每个章节采用重叠切分,按照 CHUNK_SIZE 切分,但是起点每次都会往前走 OVERLAP,也就是如果一个章节有 2500 字符,那么有如下 chunk:[0, 800)、[650, 1450)、[1300, 2100)、[1950, 2750)、[2600, none),最后一个块为空会被过滤掉
接着逐个 chunk 向量化并加入到向量数据库中,meta_data 可以带上章节标题
距离度量有:cosine、l2、ip 余弦相似度、欧氏距离、内积
这里选用余弦相似度,chromadb 在创建 collection 时就得定下度量方式
检索阶段
将用户查询 query 向量化,并在向量数据库中查找 topK 个最相近的结果
生成阶段
拼接用户消息和检索得到的结果 context 形成增强提示词,交给 LLM 生成回答
"""
简易小说 RAG
三个核心阶段:索引、检索、生成
"""
import os
import re
from openai import OpenAI
import chromadb
# ============================================================
# 配置
# ============================================================∫
NOVEL_PATH = "/Users/chanler/Downloads/西游记.txt" # 小说路径
CHUNK_SIZE = 800 # 每个分块的字符数
OVERLAP = 150 # 相邻分块的重叠字符数(向前重叠)
DISTANCE_METRIC = "cosine" # 距离度量:cosine / l2 / ip
CHROMA_DB_PATH = "./chroma_db" # ChromaDB 存储路径
# 自动生成 collection 名称:文件名_度量方式
NOVEL_NAME = "xiyouji"
COLLECTION_NAME = f"{NOVEL_NAME}_{DISTANCE_METRIC}"
# OpenAI 客户端
client = OpenAI(
base_url="http://127.0.0.1:1234/v1",
api_key="lm-studio"
)
EMBEDDING_MODEL = "text-embedding-qwen3-embedding-0.6b"
LLM_MODEL = "qwen3-8b"
# ============================================================
# 第一阶段:索引 (Indexing)
# ============================================================
def load_and_split(path, max_chapters=100):
"""
读取小说并切分为 chunks
切分策略:先按回目划分章节,章节内重叠切分
"""
with open(path, 'r', encoding='utf-8') as f:
text = f.read()
# 匹配回目标题
chapter_pattern = r'(第[一二三四五六七八九十百零\d]+回\s+[^\n]+)'
matches = list(re.finditer(chapter_pattern, text))
chunks = []
for i, match in enumerate(matches[:max_chapters]):
chapter_title = match.group(1).strip()
start = match.end()
end = matches[i + 1].start() if i + 1 < len(matches) else len(text)
content = text[start:end].strip()
# 滑动窗口切分
pos = 0
while pos < len(content):
chunk_text = content[pos:pos + CHUNK_SIZE]
if chunk_text.strip():
chunks.append((chunk_text.strip(), chapter_title))
pos += CHUNK_SIZE - OVERLAP
return chunks
def get_embedding(text):
"""获取文本向量"""
response = client.embeddings.create(
model=EMBEDDING_MODEL,
input=text
)
return response.data[0].embedding
def build_index(chunks):
"""构建向量索引"""
db = chromadb.PersistentClient(path=CHROMA_DB_PATH)
try:
db.delete_collection(COLLECTION_NAME)
except:
pass
collection = db.create_collection(
name=COLLECTION_NAME,
metadata={"hnsw:space": DISTANCE_METRIC}
)
print(f"索引 {len(chunks)} 个文本块...")
for i, (text, chapter) in enumerate(chunks):
if i % 100 == 0:
print(f" 进度: {i}/{len(chunks)}")
collection.add(
ids=[f"chunk_{i}"],
embeddings=[get_embedding(text)],
documents=[text],
metadatas=[{"chapter": chapter}]
)
print(f"完成,共 {collection.count()} 条")
return collection
# ============================================================
# 第二阶段:检索 (Retrieval)
# ============================================================
def retrieve(collection, query, top_k=3):
"""检索最相关的文本块"""
results = collection.query(
query_embeddings=[get_embedding(query)],
n_results=top_k,
include=["documents", "metadatas", "distances"]
)
return results
# ============================================================
# 第三阶段:生成 (Generation)
# ============================================================
def build_prompt(query, contexts):
"""构建增强提示词"""
context_text = "\n\n".join(
f"【{meta['chapter']}】\n{doc}"
for doc, meta in contexts
)
return f"""你是一个小说问答助手。请根据以下参考内容回答问题。
要求:
1. 只根据参考内容作答,不要编造
2. 如果没有相关信息,明确说明
3. 标注出处(回目)
参考内容:
{context_text}
问题:{query}
回答:"""
def generate(prompt):
"""调用 LLM 生成回答"""
response = client.chat.completions.create(
model=LLM_MODEL,
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
max_tokens=1000
)
return response.choices[0].message.content
def rag_query(collection, query, top_k=1):
"""完整 RAG 流程:检索 -> 增强 -> 生成"""
results = retrieve(collection, query, top_k)
contexts = list(zip(
results["documents"][0],
results["metadatas"][0]
))
prompt = build_prompt(query, contexts)
print(f"\n{'='*50}\n【完整提示词】\n{'='*50}\n{prompt}\n")
answer = generate(prompt)
return {
"answer": answer,
"sources": results["metadatas"][0],
"distances": results["distances"][0]
}
# ============================================================
# 索引管理
# ============================================================
def get_collection():
"""获取已有索引"""
db = chromadb.PersistentClient(path=CHROMA_DB_PATH)
return db.get_collection(COLLECTION_NAME)
def index_exists():
"""检查索引是否存在"""
db = chromadb.PersistentClient(path=CHROMA_DB_PATH)
try:
return db.get_collection(COLLECTION_NAME).count() > 0
except:
return False
# ============================================================
# 主流程
# ============================================================
if __name__ == "__main__":
import sys
force_index = "--index" in sys.argv
print("=" * 50)
print("简易小说 RAG")
print("=" * 50)
print(f"Collection: {COLLECTION_NAME}")
if force_index or not index_exists():
print("\n[索引阶段]")
chunks = load_and_split(NOVEL_PATH)
print(f"切分为 {len(chunks)} 个文本块")
collection = build_index(chunks)
else:
print("\n[加载已有索引]")
collection = get_collection()
print(f"已加载 {collection.count()} 条记录")
print("\n[检索与生成]")
query = "菩萨告诉孙悟空有人救他的原文句子或段落,并标注回目"
print(f"查询: {query}\n")
result = rag_query(collection, query, top_k=2)
print("="*50)
print("【参考】")
for src, dist in zip(result["sources"], result["distances"]):
print(f" {src['chapter']} (相似度: {1-dist:.1%})")
print("="*50)
print("【回答】")
print(result["answer"])
print("="*50)
我测试了 topK 分别为 1 2 3 下的回答,基本可用,实际上正确的原文段落就是 top1,top2 的情况大概是模型没理解“有人救他”要表达的意思,使用 deepseek-chat 的 API 回答就符合我的预期了
top2 情况
菩萨告诉孙悟空有人救他的原文句子是:“我奉佛旨上东土寻取经人去从此经过特留残步看你。”
出处:第八回 我佛造经传极乐 观音奉旨上长安
【参考】
第八回 我佛造经传极乐 观音奉旨上长安 (相似度: 70.0%)
第十四回 心猿归正 六贼无踪 (相似度: 69.9%)
top3 情况
菩萨告诉孙悟空有人救他的原文句子是:“你既有此心待我到了东土大唐国寻一个取经的人来教他救你。你可跟他做个徒弟秉教伽持入我佛门。再修正果如何?”
标注回目:第八回 我佛造经传极乐 观音奉旨上长安
【参考】
第八回 我佛造经传极乐 观音奉旨上长安 (相似度: 70.0%)
第十四回 心猿归正 六贼无踪 (相似度: 69.9%)
第二十一回 护法设庄留大圣 须弥灵吉定风魔 (相似度: 69.9%)
这里的相似度是因为 chromaDB 对于 cosine 近似的距离返回的是 1 - 相似度,这里只是还原
2.5 小结
到这里,我们已经跑通了简易 RAG 的流程:离线索引(切分、向量化、入库)+ 在线问答(检索、增强提示词、生成)
同时经过一系列的实践,我们也能看出许多不足,实际上有很多地方可以改进,这也就是“进阶 RAG”所要解决的问题
- 切分:如何切块保证语义连贯性(语义切分)
- 检索:如何提高检索的精确率和召回率(多路召回、Rerank 等)
- 问题:让用于匹配的 query 更清晰、可检索(提问改写、指代消解)
- 生成:如何编写提示词、组织上下文(提示词模板,引用)
- 评估:如何用指标评估 RAG(精确率、召回率、忠实度)